in last 10 minutes
Thread Mallocs for Tcl
Comparing Thread Aware Malloc Implementations for Tcl based Systems
<neumann@wu-wien.ac.at>November 2012
1. Thread Aware Memory Allocators
Since multi threaded programs share a single address space, it is necessary to use mutual exclusive locks (mutex) around shared resources to avoid inconsistencies and mutual overwrites from the running threads. The classical problem of memory allocators for multi threaded programs is to
-
execute with as little locking as possible to allow parallelism, to
-
keep memory consumption low (virtual size and resident size, memory release), to
-
support scaling for higher number of threads, while
-
keep per-thread performance high.
In practice, it is quite hard to find the right balance between these partly competing goals. Especially from long running servers the memory consumption requirements are important, since also for a server developer it is often hard to track why the memory footprint of a server grows, or at least does not shrink. There are e.g. many threads in mailing lists addressing "memory leaks" in AOLServer [1] or NaviServer [2], which might certainly exist. However, the memory usage patterns are affected substantially by the underlying memory allocation mechanism
In the little study below, we compare different memory allocators based on random and typical patterns collected from Tcl applications.
2. The Testing Scenarios
We are using a small C program which perform tests on a series of memory cells (here 64,000) from various threads. In a first step n threads are started and wait for a signal. When the signal arrives, every thread iterates over the memory cells (actually pointers) and performs malloc operations, which are interleaved with free operations. The sizes of the malloc operations are limited to 8K and are determined either via via a pseudo number generator or from a sample of 20-30 mio alloc operation collected from runs of a server application.
All tests were performed on an intel machine with 24 CPUs seen by Linux. The tested malloc implementations are:
-
zippy malloc (tcl 8.5.13, from FC 17)
-
std (dlmalloc, malloc part of libc FC 17)
-
jemalloc (3.1.0, from FC 17)
-
TCMalloc (from gperftools 2.0, from FC 17)
-
nedmalloc (1.0.5, compiled into source, newer versions cause errors)
All tests run on 64.000 memory cells.
3. Randomized Sizes
In the first test series, we compare the allocators with randomized malloc sizes up to 8K. The randomization causes the sizes to be evenly distributed.
The figure below shows for every tested memory allocator how the number of memory operations vary by the number of threads. The Y axis shows the operations/second, higher numbers are better.
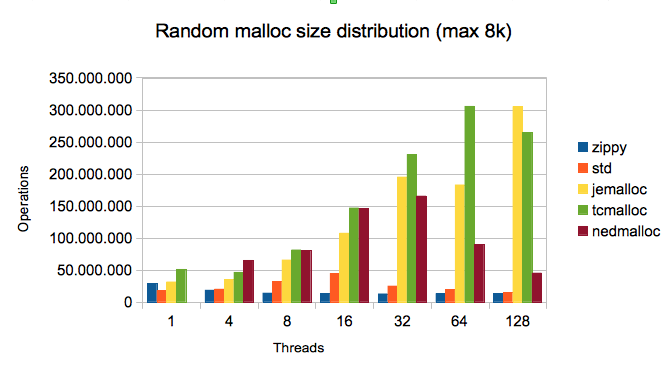
From the figure we can see that Zippy malloc is quite fast for just one thread, but for higher number of threads, other implementations are much better. Our test program had a problem with Nedmalloc and one thread, but for e.g. 4 threads, nedmalloc was the best. For higher number of threads the clear winners are jemalloc [4] and TCMalloc [5]. For 128 threads, jemalloc is on this test more than 20 times better than zippy malloc.
4. Malloc size based on Sample in a 32-bit installation
In real life applications, the malloc sizes are not evenly distributed, but the allocation units depend for scripted languages on the language implementation and the word sizes of the machines. In the second test series, we compare the allocators based on a sample we took several years ago on a run of OpenACS [3] under AOLServer 4.5. OpenACS is quite a large multi threaded Tcl application. The connection threads and scheduler threads are initialized with a blueprint containing often more than 10.000 procs (Tcl function definitions). In a sample run we collected the sizes of 30 mio malloc operations and used these sizes to distribute the sizes of our test program. Here 43 percent of the malloc operations had a size of 32 bytes, followed by 7 percent 12 byte mallocs and 4 percent 20 byte mallocs.
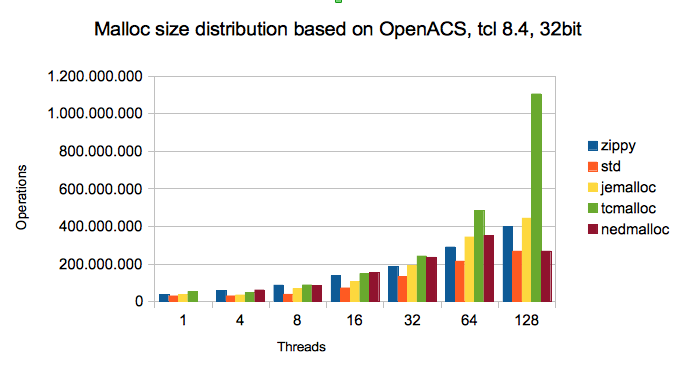
From the figure we can see that Zippy malloc is among the best three (often the best) for 1 to 128 threads. For higher number of threads, TCMalloc (from the Google performance toolkit [6]) is the clear winner. jemalloc is as well among the best.
5. Malloc size based on Sample in a 64-bit installation
In the third test series, we compare the allocators based on a sample of a run of OpenACS under NaviServer 4.99.4 with Tcl 8.5.13 on a 64 bit machine. This sample contains 24 million entries. The change caused that a smaller fraction of small malloc operations: nearly 10 percent of the malloc operations had a size of 32 bytes, followed by 7 percent 56 byte mallocs and 6 percent 40 byte mallocs.
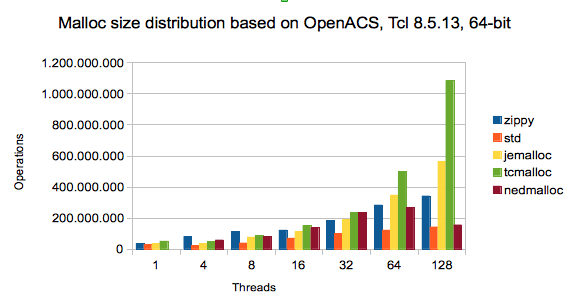
From the figure we can see that Zippy malloc is still among the best three (often the best) for 1 to 128 threads. For higher number of threads, jemalloc is gradually better than on the 32-bit test. For 128 threads, TCMalloc’s performance is the same as in the 32-bit test, while the results of jemalloc are better, while the the results all other allocators are worse.
6. Comparing Memory Sizes
Finally we compare the memory sizes depending on the malloc implementations. For this test we used the previous sample (of OpenACS under NaviServer 4.99.4 with Tcl 8.5.13 on a 64 bit machine). The memory footprint is usually measured by the Resident Set Size (RSS) and the virtual size (VSize, often VSZ).
-
The Resident Set Size (RSS) is the amount of memory used currently in RAM determined by the active pages. This number contains as well the code segment pages.
-
The Virtual Size (VSize) is virtual memory size of the process. VSize denotes the entire virtual memory size, no matter whether the pages are loaded into memory or the actual memory or not.
RSS and VSize are determined by our test program via the proc file system (/proc/self/stat). For the Figures below, smaller figures are better.
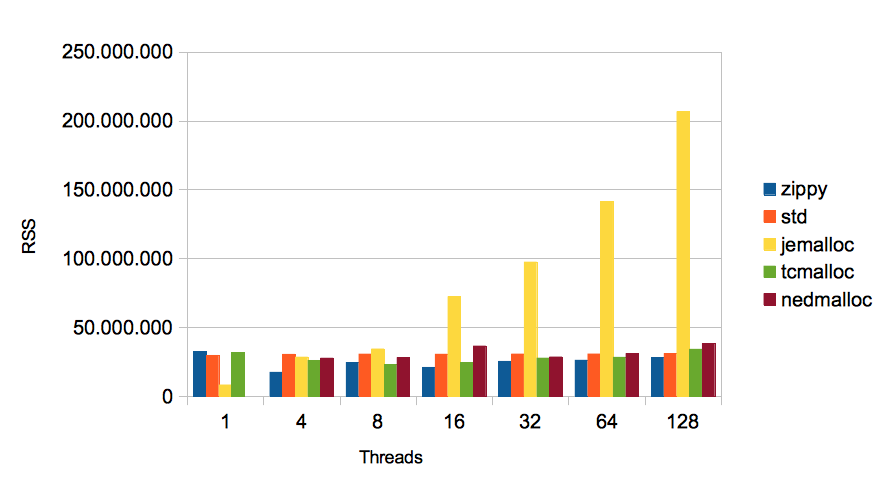
The most relevant figure is RSS. In the Figure 4 above it is interesting to note, that using jemalloc lead to the lowest memory consumption of a single thread, but to the highest one at 128 threads. When looking at the RSS size for zippy, we see that it is the best for 4 threads or more. Keeping aside the jemalloc, the differences are not very large.
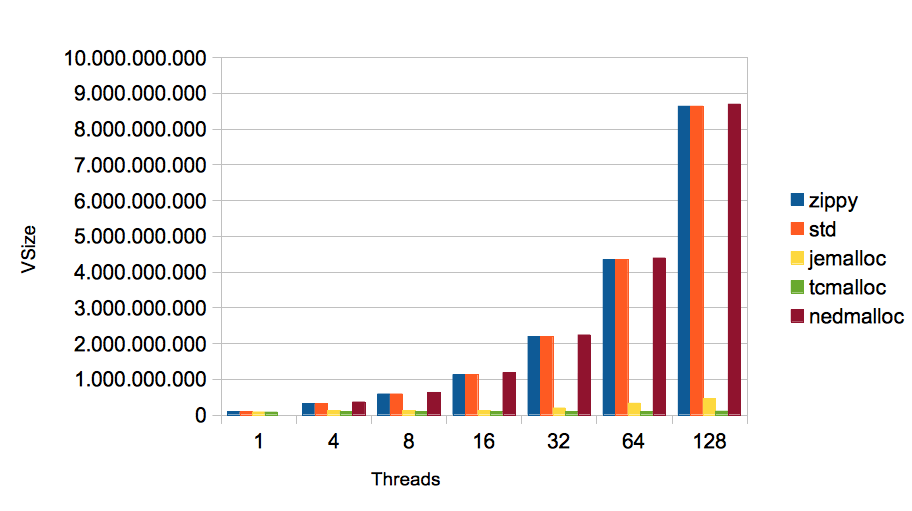
When looking the at sizes of the full virtual memory, we can see that Zippy, std and nedmalloc behave drastically different to jemalloc and TCMalloc. For 128 threads when e.g. zippy is used, the size of the process is 82 times the size of the process with TCMalloc. On can certainly argue how important VSize is on modern operating systems. In terms of scalability the values measured with jemalloc and especially TCMalloc look better.
7. Other Factors
Especially for long running servers, memory release is important as well. Zippy malloc has the bad property that it keeps freed memory in its pool. The consequence is that when threads terminate, the memory allocated by these threads does not shrink the memory footprint. If the threads contain substantial code (e.g. several thousand procs as in OpenACS), the observed memory footprint is determined by the maximum number of threads ever run. For a long running web-server this means, a short burst of requests let the server grow in memory "forever". Therefor, it is today more or less impossible to run a substantial OpenACS installation on a 32 bit machine without running into the 2GB limit of the maximum process size.
The test above do not try to measure the memory release rate of the malloc implementations, since this requires more or less longer running programs. The the leading malloc implementation jemalloc and TCMalloc both release memory back to the OS (e.g. tunable via TCMALLOC_RELEASE_RATE in TCMalloc).
8. Summary
When googling around, one finds many tests of various memory allocators. In many cases, it is not easy to determine which exact versions were tested on which operating system on what kind of data. These tests come to different conclusions, what the best memory allocator is. For some of the conclusions (e.g. TCMalloc leads to a memory bloat on longer running systems) we found on our tests an applications no evidence with recent versions. We had some troubles with the stability of nedmalloc, we finally used 1.0.5, which still had problems in the single thread case.
The test cases above show, that the test scenario has a substantial influence on the results. We see quite different results when allocating evenly distributed memory sizes or when allocating memory sizes based on real sample data.
The threaded memory allocator of Tcl (Zippy) works quite well on the sample patterns, while being much worse on random sizes. For long running applications like OpenACS on NaviServer/AOLserver, the biggest disadvantage of Zippy is that it is not returning memory to the OS. It requires - like many other malloc implementations as well - a huge virtual memory size, which can cause a system to run out of memory.
A final word of caution: the test above are designed to put a strong pressure from multiple threads to the memory allocation subsystem. For real application, there will be certainly less concurrency pressure, even when running the same number of threads. When using these memory allocators, don’t expect the same benefits or penalties when running your own applications, but test yourself.
9. References
[1] AOLserver: http://www.aolserver.com/
[2] NaviServer: https://sourceforge.net/projects/naviserver/
[3] OpenACS: http://openacs.org/
[4] jemalloc: http://www.canonware.com/jemalloc/
[6] Google Performance Toolkit: http://code.google.com/p/gperftools/